Développement de systèmes automatiques d’évaluation du risque en leucémie myéloïde aiguë à partir de données d’expression de gènes
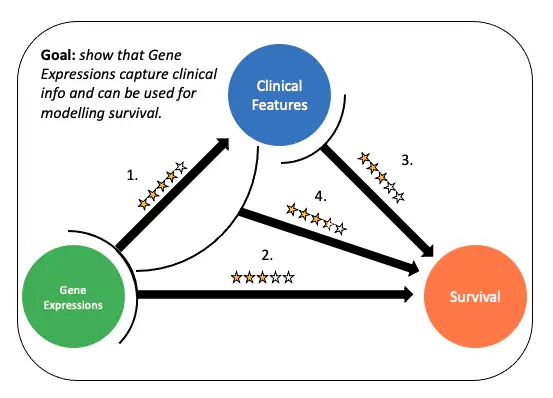
En Amérique, des milliers d’adultes reçoivent un diagnostic de leucémie myéloïde aiguë (LMA) chaque année, dont seulement 28 % survivront après cinq ans. Ce type de cancer, qui affecte les globules blancs sanguins, est génétiquement hétérogène, rendant les traitements contre certains types adverses de la maladie inefficaces. Nos analyses informatiques ont pour objectif de raffiner les sous-types de LMA pour guider le développement de traitements ciblés et de meilleurs succès thérapeutiques. Pour ces analyses, nous nous intéressons aux données provenant de la cohorte Leucegene, comprenant quelques centaines d’échantillons d’expression de gènes de cellules de LMA ainsi que des annotations cliniques. Ces données ont un énorme potentiel pour développer des approches d’apprentissage automatique profond permettant l’identification rapide du risque cellulaire découlant des sous-types de la maladie. Ces développements pourraient être éventuellement intégrés au processus de triage actuel performé par les cliniciens et les assister à définir un protocole de traitement adapté. Nos approches bio-informatiques et d’apprentissage profond essaient de répondre aux défis inhérents aux données que nous traitons. Il s’agit notamment du grand nombre de variables d’entrées aux modèles, du grand nombre de patients dans la cohorte et à la particularité des données de survie d’être parfois censurées ou incomplètes. De plus, nous tentons de mettre au point des protocoles qui corrigent les artefacts expérimentaux introduits par l’intégration de jeux de données de sources différentes appelés batch-effects. À ce jour, un modèle utilisant une régression à risque proportionnel de Cox et une analyse en composantes principales sur les données d’expression nous permettent de modéliser le risque dans la cohorte Leucegene. Ce modèle confirme que les données d’expression capturent les informations cliniques et ajoutent de la précision pour l’évaluation du risque en LMA. Présentement, des analyses sont en cours visant l’utilisation d’un réseau de neurones artificiel pour modéliser le risque en LMA, ce qui pourrait considérablement améliorer la performance du modèle actuel.